%20(58).png)
This guide is part of an FT Strategies series exploring the AI technologies reshaping news publishing. Each edition explains an emerging technology often misunderstood by journalists and editors — from AI engines to liquid content and from agentic systems to MCP servers — before outlining how it can be applied across editorial, commercial and product functions. Get in touch if you have specific technologies or terminology that you’d like us to cover.
Why should news publishers be paying attention to AI engines?
Much has been written about how AI platforms, such as Google’s Gemini or OpenAI’s ChatGPT, are rapidly changing the ways that consumers expect to get their news, whether in terms of content format, speed, or style.
AI engines, often understood as the systems that bring together underlying AI technologies, offer ways for publishers to keep up with these changes by optimising both internal (e.g. data collection and analysis) and audience-facing (e.g. content verification or recommendation) processes.
However, we have found that AI engines can often seem opaque because they act as the underlying forces to more frequently-discussed topics, like AI agents and liquid content. It’s for this reason that we created this guide.
First things first, how does an AI engine work?
An AI engine is a name that we assign to a kind of execution system that hones an LLM’s abilities towards specific goals. It acts like a control room placed on top of the model, calling the shots of what happens beneath it.
You can imagine an AI engine a bit like the conductor of an orchestra. It directs the different instruments — the many infrastructure layers beneath an AI system — so they work together to produce a single piece of music, or output. And just as orchestras change their line-up depending on the music, AI systems vary according to the task at hand.
Like orchestras, an AI engine does not build a fresh set of musicians every time it is asked to play music. Instead, it works with an existing ensemble, managing the relationships with a broader model or LLM rather than recreating the underlying system itself.
Thinking about AI engines in this way is a useful framing because it reminds us that, at its core, these new types of AI systems have the same underlying technologies under the hood.
What kind of engines are out there?
There are all kinds of engines out there with a number particularly relevant to news publishers and wider publishing businesses:
|
Engines |
Definitions |
Currently used by publishers? |
|
Workflow engines |
Control and automate digital workflows, sometimes using agents. |
Yes, and are starting to be supplemented with agentic capabilities. |
|
Context engines |
Decide what kind of context is necessary for specific queries. Can be thought of as a more sophisticated RAG with the ability to manage internal and external agents. |
Yes, in the form of early context engines via RAG. |
|
Agent orchestration |
Teams of agents that are made up of one “orchestrator” agent that coordinates several sub-agents. Sub-agents can work in parallel and specialise in various capacities. |
No. Though individual agents have been deployed, we have not yet seen orchestrated teams notably used. |
|
Experience engines |
Charged with making content liquid and malleable across formats, as well as ensuring the faithfulness of content transformations. |
No. While some examples of liquid content exist, such as The Washington Post’s “Your Personal Podcast”, there is yet to be a full-scale experience engine deployment. |
|
Decision engines |
Use propensity and churn data to determine what kind of content should be served to audience sub-groups. |
No. There have been no public examples of true hyper-personalisation using decision engines. |
|
Trust engines |
Means of building AI failsafes into every step of digital workflows to ensure data safety, verification, and hallucination guardrails |
No. Though some examples of trust mechanisms are becoming embedded in workflows, more intensive trust engine systems are not yet popular. |
We’ll go through each of them in turn to explain how they can be useful.
Engines currently used by publishers:
- Workflow engines
As the name suggests, workflow engines offer a means of automating digital workflows. While they have existed in some manner or other for a long time, recent AI-strapped workflow systems have allowed for more complex and layered reasoning. In practice, that means workflows that can actively make decisions and contribute to your workflow beyond just moving processes forward.
There are many workflow engine platforms currently being used in the media industry and beyond, including Apache Airflow, N8n, and Zapier. While these platforms are user-friendly, we recommend considering building your own workflow to prevent reliance on third-party organisations that could be discontinued at short notice.
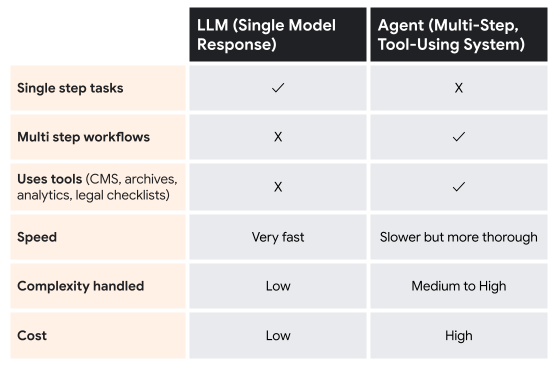
Recently, more intensive AI-assisted workflow engines have been developed thanks to the recent popularity of AI agents. Unlike workflow engines, which remain somewhat passive ways of expediting work pipelines, agents play a much more active role in decision making and tool use; in other words, agents are unique in that they are granted agency in workflow processes.
Agents have become useful as of late because they are now programmed and operate via a ReAct framework, i.e., they can first “reason” through a task, then “act” on that reasoning, looping back and making adjustments as needed. Combining workflow engines with agentic capabilities has allowed for more useful systems, especially as these agents become a kind of “workflow runner” for the broader engine. For example, if a workflow engine is tasked with highlighting potential news stories for journalists, it could utilise an agent to monitor the Internet for relevant breaking news topics.
You can think of it as a coordinated road trip: the workflow engine knows where the car needs to go and can provide the map. The agent, on the other hand, is driving the car and is in charge of actually completing the journey as designated by the workflow engine. If, however, the agent takes a wrong turn, it can figure out how to double back and correct its course thanks to its ReAct framing.
-1.png?width=323&height=361&name=Emerging%20Tech%20Blog%20One%20(1)-1.png)
- Context engines
Context engines are meant to handle backend data, such as newsroom data or content archives, deciding what kind of context is necessary for specific queries. In other words, it is the system in charge of filtering between essential background information and unrelated information given the request. When it comes to AI systems, this kind of information management is incredibly important, as it prevents “context overload,” or an excess of information that ultimately works against the system’s response to a query.
A familiar component of context engines within newsrooms is retrieval-augmented generation, or RAG. RAG is a subclass of, or stand-in for, context engines in newsrooms today. RAG operates as a kind of “newsroom memory,” and is the system in charge of filtering through internal newsroom data to pull relevant information for user queries.
RAG’s abilities will likely improve in the coming years, allowing for things like multimodal data collection, decreased retrieval latency, and better context distillation. This will allow news publishers to quickly sort through and collect relevant data across different formats.
However, as agentic AI becomes more popular, there is a need for more holistic context engines beyond RAG. This kind of more complex context engine system will become essential to manage the coming influx of both visiting agents and internal agents that are making data queries. More specifically, we will likely see a future in which the context engine is not just charged with surfacing relevant content, but also ensuring that external agents are correctly accessing or paying for newsroom data.
Engines yet to impact publishing:
While workflow and context engines have been utilised in the news publishing for some time, other AI engines and systems have yet to significantly impact how media is produced and distributed. Here are some things we are starting to see emerge:
- Agent Orchestration
“Agent” has become a buzzword term in the industry, but more advanced uses of agents consist of a team of agents. This has led to Agent Orchestration developing as a use case in newsrooms.
Unlike single agents, which are often assigned to fragmented tasks that are completed sequentially, orchestrated agentic systems are composed of one root (or “orchestrator”) agent that coordinates several sub-agents. This kind of pyramid structure allows for several enhanced capabilities, such as parallel processing, sub-agent specialisation, longer-form tasks, and more.
-1.png?width=750&height=192&name=Emerging%20Tech%20Blog%20One%20(2)-1.png)
(Anthropic’s 2026 Agentic Coding Trends Report)
However, as always, increased capacity comes with tradeoffs: while single-agent systems use about 4x as many tokens as LLM-based chatbots, multi-agent systems use about 15x more tokens. That means more compute power, higher costs, and ultimately, only using orchestrated agentic systems when it is well worth it.
- Experience and Decision Engines
Another popular industry term lately is liquid content, or content that can easily flow between format styles. While there are debates on the specific definition of liquid content and whether it means multimodality or personalised content, we call the technology that handles these transformations an Experience Engine. Experience Engines are not only charged with making the content malleable, but further ensure that any changes made are still faithful to the original piece of journalism.
Many newsrooms have already experimented with forms of liquid content in the past couple of years. However, the new development we are starting to see is the combination of Experience Engines with something called Decision Engines.
Decision Engines are used to improve dynamic decisions given a set of relevant circumstances and background data. As a result of their underlying AI infrastructure, Decision Engines can be incredibly adaptive to quick changes.
By coupling Decision Engines together with Experience Engines, new possibilities emerge in terms of determining how to best to format content in a way that will engage an end user. More specifically, an Experience Engine could adapt an article into several different format types, while the Decision Engine considers real time using data to determine which formats should be shown to which users.
-1.png?width=450&height=378&name=Emerging%20Tech%20Blog%20One%20(3)-1.png)
Through these combined systems, a more generative UI will emerge for readers, with the capacity to predict what format a user will want and change accordingly.
- Trust Engines
Finally, amidst these growing AI uses, we must prioritise the trust that grows alongside them. A Trust Engine is a way of building safety and verification methods into every step of the publishing workflow. Importantly, Trust Engines are intended to work within the pipelines that are already in place in newsrooms. Rather than a one-stop-shop verification or audit at the end of an AI use case, Trust Engines ensures that every step in the process builds in AI governance.
This could mean immediate data verification of external sources to detect deepfakes, or toxicity detection schemas when information is fed back from AI platforms. It could also mean publishing organisations integrating more holistic systems of data provenance, or of tracking data and its metadata through the lifecycle to verify authenticity.
Where do we start?
To start playing with some of these ideas, we recommend familiarising yourself with the following resources:
- Florent Daudens’ AI Agent Tutorial Series or Google’s Cloud services information on agents for helpful walkthroughs on developing agents specifically for newsroom contexts.
- Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems by Antonio Gullí and Hugging Face’s AI Agent Course are a good place to start for more intensive AI scaffolding.
Many of these technologies are still emerging and industry applications are evolving at speed. We’ll update this guide as best practices and case studies emerge.
At FT Strategies, we assist publishers in transforming emerging AI concepts into actionable strategies. This includes developing workflow and context engines that enhance today’s newsrooms, as well as pioneering systems such as agent orchestration and experience and trust engines. Our aim is to simplify complex processes and unlock genuine editorial, product, and commercial value.
If you’re considering how to integrate AI engines into your organisation, please get in touch for support in transitioning from experimentation to implementation. We can help you build the capabilities needed to ensure high-quality, trusted journalism.

%20(2).png?width=768&name=Hero%20Image%20(website%20banner)%20(2).png)
